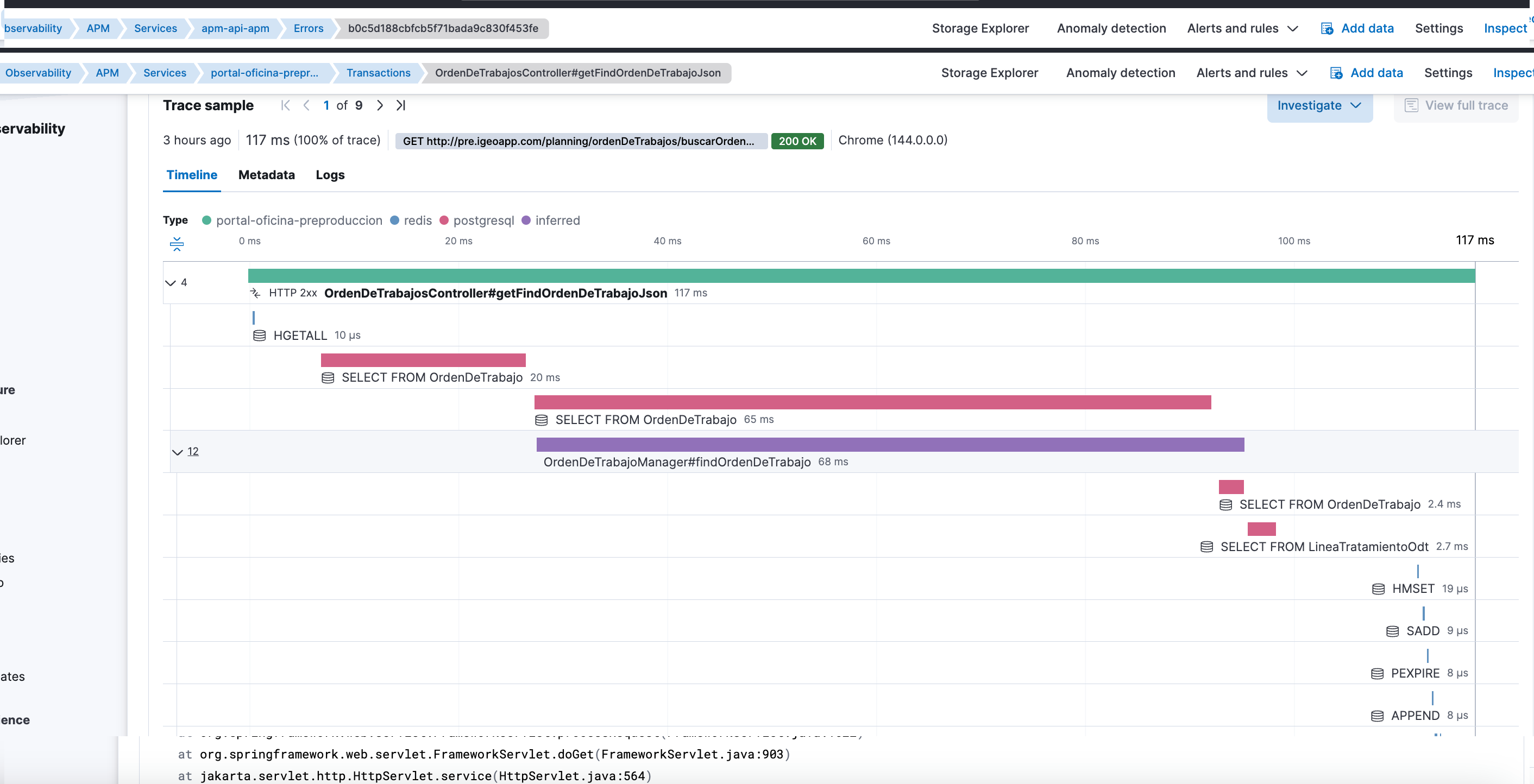
Elastic APM estaba funcionando. Las transacciones aparecían. Las llamadas entre servicios se veían con bastante claridad.
Y aun así, había algo profundamente frustrante: los errores no aparecían.
La aplicación tenía excepciones reales, visibles en los logs, pero en la UI de APM:
- No había errores.
- No había stacktraces.
- Las trazas parecían “limpias”.
El problema no era evidente. Y tampoco estaba donde yo pensaba.
El contexto
Estaba integrando Elastic APM en una aplicación Java sobre Tomcat.
La integración básica era correcta:
- El agente APM arrancaba sin errores.
- APM mostraba servicios y transacciones.
- Las peticiones se trazaban correctamente.
A nivel superficial, APM funcionaba. A nivel diagnóstico, no.
El síntoma real: trazas sin contexto de error
Las trazas mostraban:
- Duraciones.
- Llamadas.
- El flujo general de la petición.
Pero faltaba lo más importante cuando algo fallaba:
- Ningún error asociado.
- Ningún stacktrace.
- Ninguna pista clara del motivo real del fallo.
Esto es especialmente engañoso porque APM no estaba vacío. Estaba incompleto.
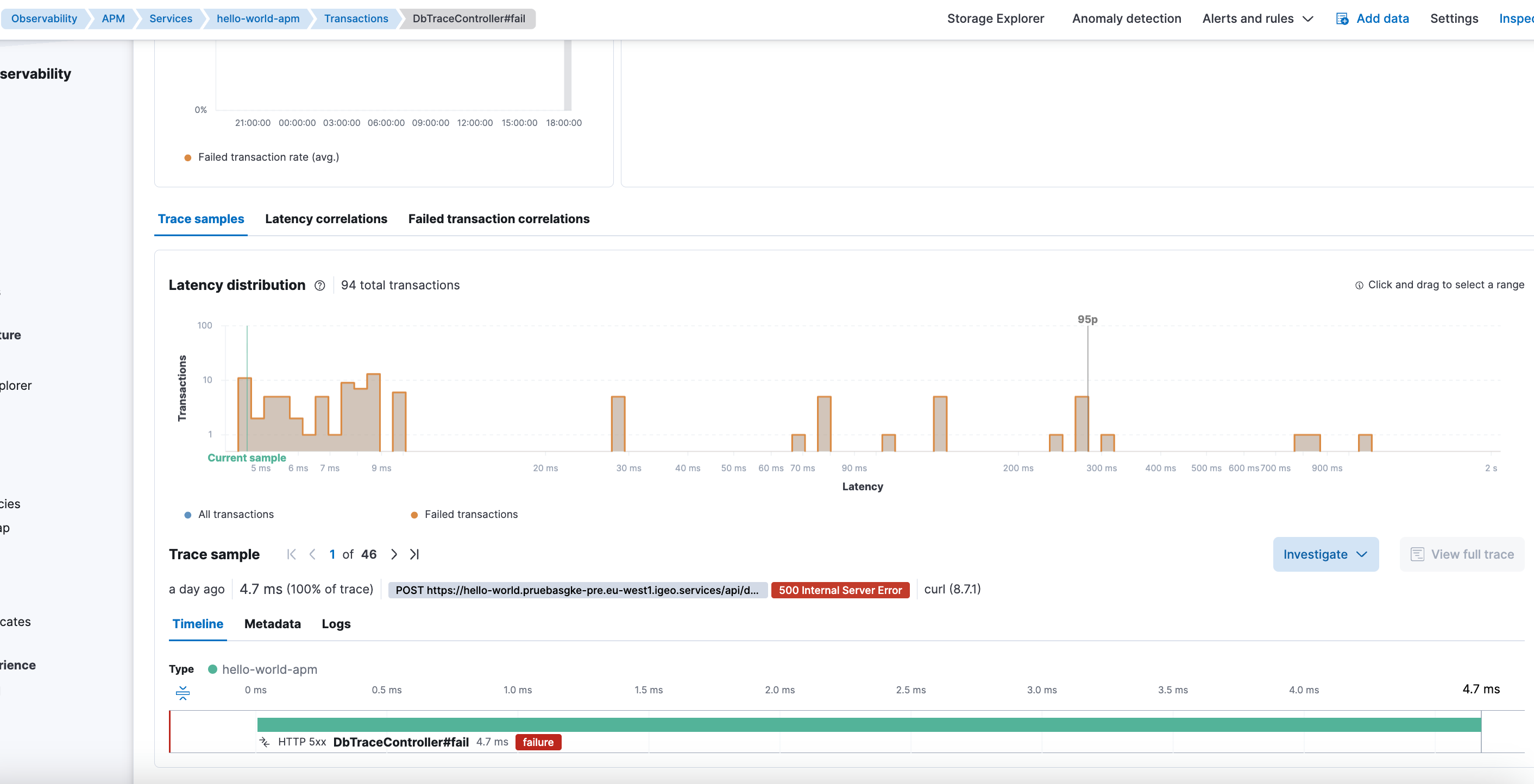
Primer impulso: añadir más instrumentación
Mi primera reacción fue pensar que el problema era de detalle insuficiente en las trazas.
Probé inicialmente a forzar instrumentación con:
ELASTIC_APM_TRACE_METHODS=com.pierinho13.*#*
El resultado fue inmediato, pero poco útil a largo plazo:
- Muchísimo más detalle.
- Demasiados métodos instrumentados.
- Un volumen de spans difícil de manejar.
- Ruido excesivo para un entorno real.
APM dejaba de ser una herramienta de diagnóstico y pasaba a ser un volcán de datos.
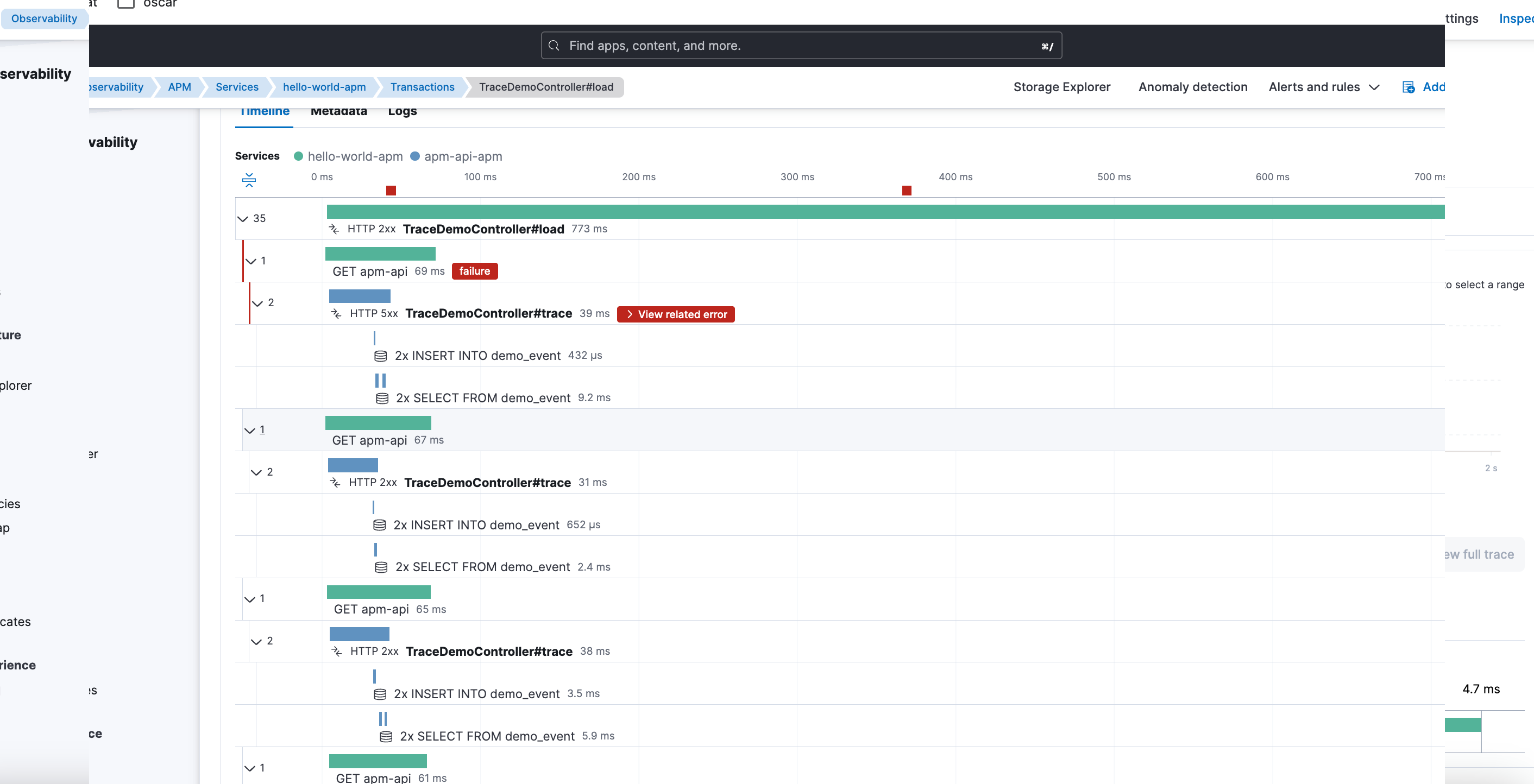
Un mejor equilibrio: inferred spans por profiling
Buscando una alternativa más razonable, activé inferred spans mediante profiling:
- name: ELASTIC_APM_PROFILING_INFERRED_SPANS_ENABLED
value: "true"
- name: ELASTIC_APM_PROFILING_INFERRED_SPANS_MIN_DURATION
value: "10ms"
- name: ELASTIC_APM_PROFILING_INFERRED_SPANS_SAMPLING_INTERVAL
value: "50ms"
Aquí hubo un cambio claro:
- Las trazas empezaron a mostrar mucho más detalle interno.
- El recorrido real de la petición se entendía mejor.
- Sin el coste ni la verbosidad de TRACE_METHODS.
APM empezó a ser realmente útil.
Pero los errores seguían sin aparecer.
El error de enfoque
En ese punto estaba claro que:
- El agente funcionaba.
- La instrumentación funcionaba.
- Las trazas se generaban correctamente.
El problema no estaba en cómo se capturaban los datos, sino en qué pasaba con ellos después.
El verdadero causante: templates e ILM pisando APM
La causa real no estaba en APM, sino en la gestión de logs.
Había un template genérico para logs-*-* con una prioridad más alta que los templates específicos de APM.
Eso hacía que, para data streams como logs-apm.error-*, ganara el template genérico en lugar del que Fleet y APM esperan.
Además, las operaciones de ILM se aplicaban de forma indiscriminada a todos los data streams bajo logs-*, incluyendo los de APM, que tienen:
- Pipelines específicos.
- Mappings concretos.
- Políticas de lifecycle propias.
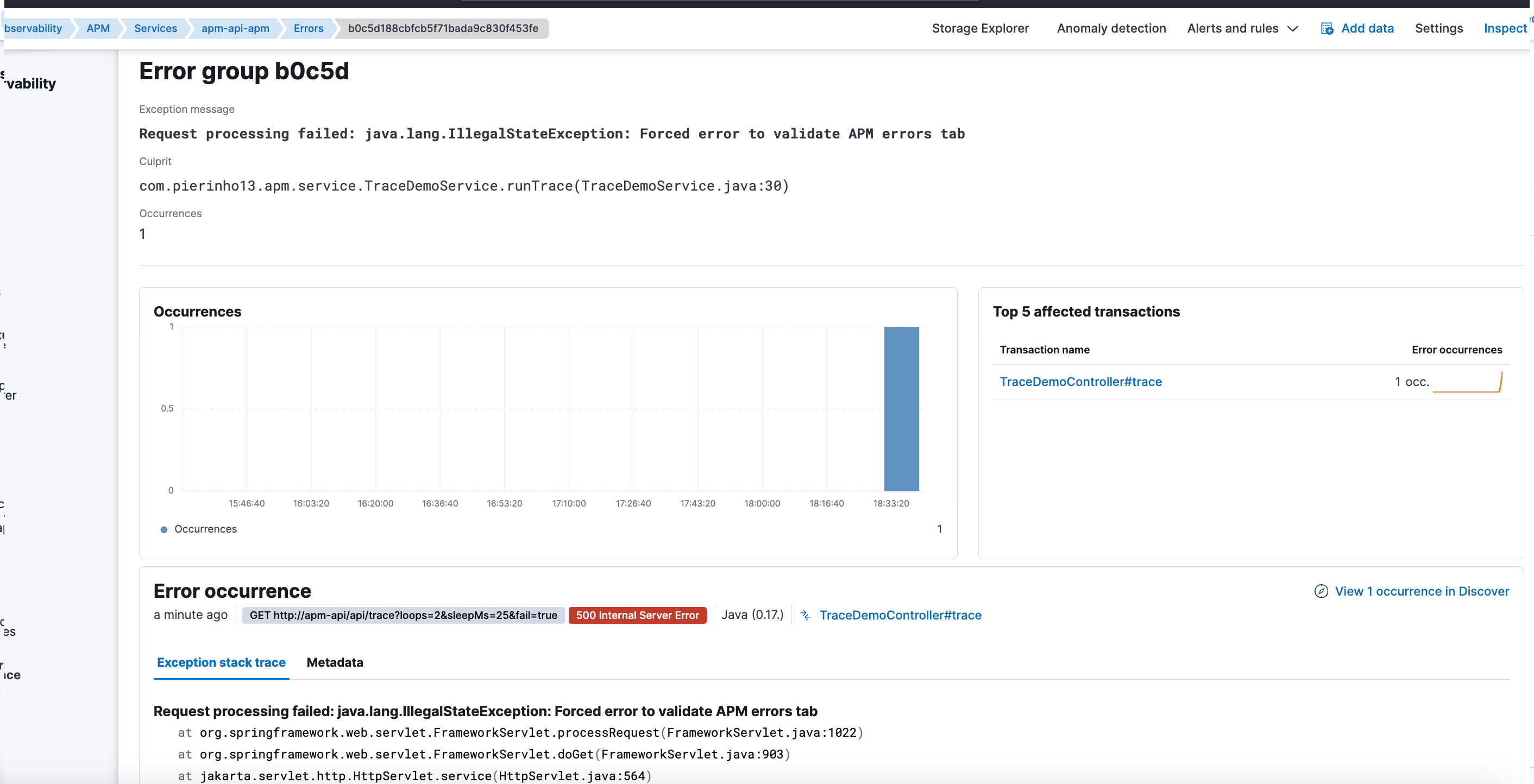
El efecto era silencioso pero devastador:
- Las transacciones seguían apareciendo.
- Las trazas seguían visibles.
- Pero los errores y stacktraces quedaban degradados o directamente invisibles.
Por qué APM parecía “vacío” al filtrar
La UI de APM depende críticamente de campos como:
service.nameservice.environment
Cuando los templates de APM eran pisados:
- Estos campos dejaban de comportarse como APM espera.
- No eran agregables de la forma correcta.
- Los filtros por servicio o entorno no devolvían resultados.
Desde Kibana, la sensación era clara:
No hay errores.
En realidad:
Los errores existían, pero APM no podía representarlos correctamente.
Por qué este problema es tan difícil de detectar
Elastic no lanza alertas por esto. No hay errores evidentes. No hay mensajes claros en la UI.
APM simplemente deja de mostrar parte de la información.
Y eso es lo más peligroso:
- Crees que el problema es el agente.
- Ajustas instrumentación.
- Cambias sampling.
- Añades profiling.
Cuando el problema real está en el ciclo de vida y los templates del dato.
El aprendizaje real
Este caso dejó varias lecciones importantes:
- APM puede funcionar de forma parcial y aun así parecer “correcto”.
- Ver transacciones no garantiza ver errores.
- Añadir más instrumentación puede mejorar el detalle, pero no arregla problemas de ingestión o lifecycle.
- Los templates y políticas ILM de APM no son intercambiables con las de logs genéricos.
Y la más importante:
En observabilidad, no basta con que los datos lleguen. Tienen que llegar con la forma exacta que la herramienta espera.
Cierre
Elastic APM estaba haciendo su trabajo desde el primer momento. Los errores también existían.
El problema era menos visible y más peligroso: una configuración genérica de logs que degradaba silenciosamente APM.
A veces el problema no es que no se generen, sino que se procesen de forma correcta.
Si estás operando Elastic y encuentras problemas similares en APM o observabilidad, puedes contactarme.